Guide to Scrape Data from an Investment Stock Website
- 6 minsTo understand the stock market, my elder brother Anthony gives me monthly assignments to research the stock exchange in Malaysia. And I have to report 2 to 3 stocks and give legit reasons why I chose them before purchasing one. But my monthly research involves repeating the same steps:
- Go to the stock investment portal
- Open multiple links that analyst recommends to buy
- Compile a list of quality stocks with good reasons
To save me the hassle of repeating the same steps I created a Python script and be done with the assignment as soon as possible (because I am lazy). For now, this script can only do step 1 and step 2. Keep in mind this post is catered towards Mac / Ubuntu users.
Unfortunately, i3investor does not have an API, but all is well. My approach is to mine, data using webscraping method.
First, let’s look at the repeated steps that I have to go through each time. If you go the portal, you can see the following table that looks this:
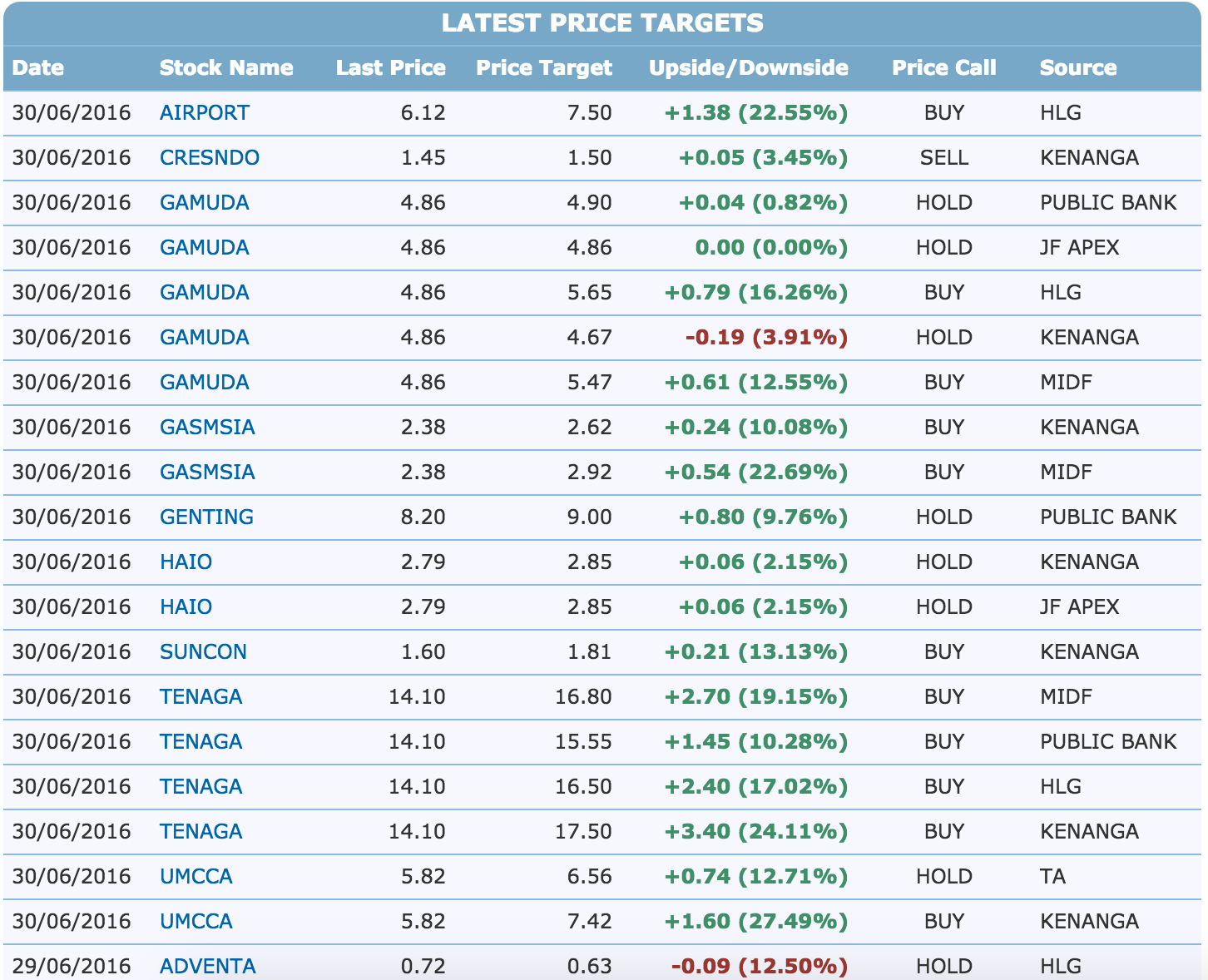 Screenshot 6/30/2016 from Joshua’s Macbook
Screenshot 6/30/2016 from Joshua’s Macbook
As you know, there are many stocks to choose from and the ‘Price Call’ tab represents what analysts from different professional firms have to say about the particular stock. So what I usually do is to open multiple tabs that have ‘BUY’ as the keyword at the ‘Price Call’ tab.
What my script does is that it connects to the stock portal and opens all stocks that the analyst says ‘BUY’ in different tabs. The result looks like what you think it is.
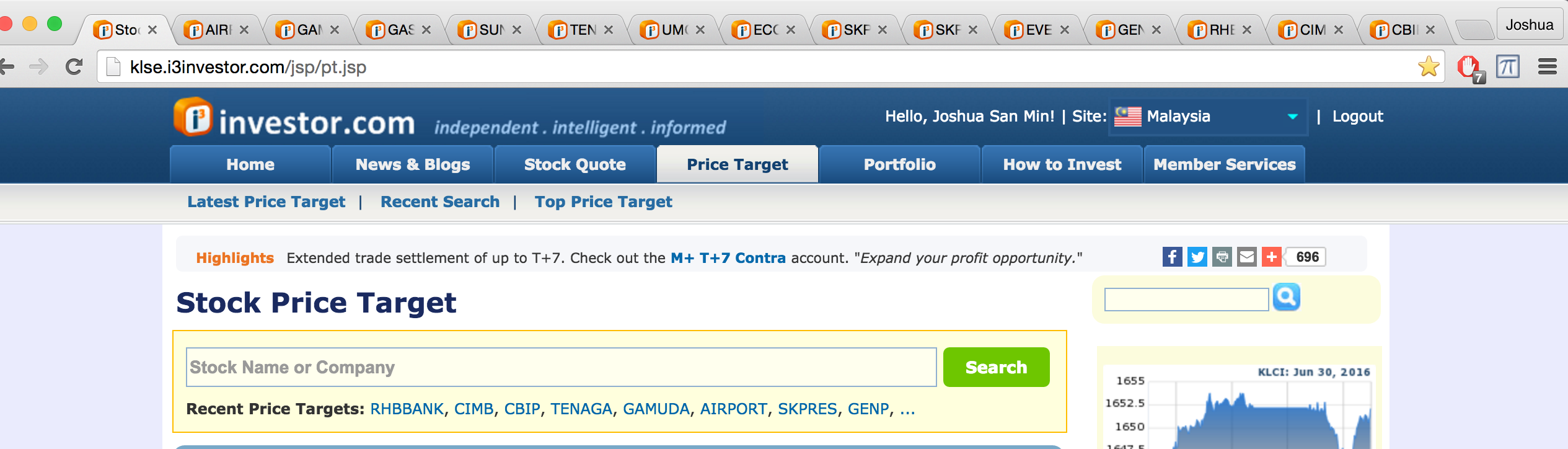
Sounds easy enough? Good, you’re getting there.
Step 1:
Before you we go into details you would need to install lxml, requests , and BeautifulSoup on your Terminal:
pip install lxml
pip install requests
pip install BeautifulSoupStep 2:
Alright let’s start coding, we need to import these libraries for the python module to work.
import requests
from BeautifulSoup import BeautifulSoup
import lxml.html
import webbrowserStep 3:
We then need the script to connect to the portal. I took the actual URL and hard coded it in. The 1st function looks like this
def connectAllPriceTarget():
global soup
priceTargetUrl = 'http://klse.i3investor.com/jsp/pt.jsp' # get url
page = requests.get(priceTargetUrl) # connect to page
html = page.content # get html content
soup = BeautifulSoup(html) #beautify the html pageStep 4:
Once the script is connected to the website, web scraping begins here. If you see the actual page source of this site, it looks ugly. BeautifulSoup does a good job ‘beautifying’ the HTML page for your convenience
To understand the different tags and to know which one to scrape, I created the html page from below :
with open("allPriceTarget.html", "w") as myfile:
myfile.write(soup.prettify())Here’s a snapshot of before / after look on the html file:
before:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head> <title>Stock Price Target | I3investor</title> <meta http-equiv="content-type" content="text/html; charset=utf-8" /> <meta http-equiv="X-Frame-Options" content="deny"/> <meta name="description" content="A free and independent portal for stock investors. The portal provides aggregated investment Blogs and News, Stock Database & Quotes, Price Targets, and Watchlist/Portfolio tool for investors." /> <meta name="keywords" content="Stock Price Target,Bursa Malaysia" /> <link rel="icon"after :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>
Stock Price Target | I3investor
</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<meta http-equiv="X-Frame-Options" content="deny" />
<meta name="description" content="A free and independent portal for stock investors. The portal provides aggregated investment Blogs and News, Stock Database & Quotes, Price Targets, and Watchlist/Portfolio tool for investors." />
<meta name="keywords" content="Stock Price Target,Bursa Malaysia" />
Once I know which specific tags to scrape, I start compiling the links to these stocks in a list
def compileStocksAndLinks():
table = soup.find('table', {'class': 'nc'})
#for each row, there are many rows including no table
global stockNames, priceTargetLinks
stockNames = []
priceTargetLinks = []
for tr in table.findAll('tr'):
center = tr.find('td', {'class': 'center'}) # for each center
# not all rows have 'center' (price call)
if(center and center.text == "BUY" and tr.find('a').get('href') not in priceTargetLinks):
leftTag = tr.findAll('td', {'class': 'left'}) # find all 'left' that in that row
stockNames += [leftTag[1].text]
priceTargetLinks += [tr.find('a').get('href')]I now have a list of stock names and their corresponding Price Target links
Step 5:
The last function is to simply open each link in different tabs using the webbrowser library in Python
def openPriceTargetLink():
for link in priceTargetLinks:
url = 'http://klse.i3investor.com' + link
webbrowser.open(url, new=0, autoraise=True)Step 6:
Okay, all I need to do know right now is to call these 3 functions and boom! script success, time to research stock = reduced
connectAllPriceTarget()
compileStocksAndLinks()
openPriceTargetLink()
Joshua Liew
Your friendly Computer Engineer